【正規表現】正規表現でよく使いたいものまとめ①
正規表現というのは、使う時と使わない時の期間が空きすぎて結局忘れてしまうんですよね。。
なので、正規表現を使う場面を自分的に整理して、まとめようと思います。
(この表現のほうが効率いいじゃん!と思ったら記事を更新しますので、あくまで参考としてください。)
~が含まれているが、~が含まれていない場合は抽出したい
私の経験の中で一番使いたいなと思うシーンです。
つい先日、何気なく本ブログのアクセスログを確認すると、何か攻撃されているっぽい(笑)となりました。
以下のような感じで、脆弱性があるとされているファイルにGETやらPOSTやら、やりたい放題やられていたわけです。orz
xx.xx.xx.xx – – [09/Feb/2024:02:33:47 +0900] “GET /wordpress/xmlrpc.php HTTP/1.1” 404 5148 “-” “Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.30729; .NET CLR 3.5.30729; rv:11.0) like Gecko”
xx.xx.xx.xx – – [09/Feb/2024:02:33:49 +0900] “GET /old/xmlrpc.php HTTP/1.1” 404 5148 “-” “Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0”
xx.xx.xx.xx – – [09/Feb/2024:02:33:50 +0900] “GET /new/xmlrpc.php HTTP/1.1” 404 5148 “-” “Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36”
xx.xx.xx.xx – – [09/Feb/2024:02:33:51 +0900] “GET /blog/xmlrpc.php HTTP/1.1” 404 5148 “-” “Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:79.0) Gecko/20100101 Firefox/79.0”
xx.xx.xx.xx – – [09/Feb/2024:03:14:41 +0900] “GET /wp-sitemap-posts-post-1.xml HTTP/1.1” 200 799 “-” “Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) Chrome/116.0.1938.76 Safari/537.36”
※xx.xx.xx.xxは実際はipアドレスですが、マスクしています。
腹が立ちますが、攻撃されたログを解析して対策を打とうと思った際に、正規表現が必要となったわけです。
ログを見ていると、
①xx.xx.xx.xxのipアドレスからのアクセスが半端なく多い = xx.xx.xx.xxで始まる1行を見つけたい
②不正アクセスは、「アクセス元のURL」がなく、「”-“」と表示されているようだ
が条件として浮かび上がってきます。
「xx.xx.xx.xx」が含まれた行だけを検索すると以下のようになってしまい、不正アクセスではないものまで抽出されます。

なので、「xx.xx.xx.xxが含まれているが、不正アクセスでない箇所は含まない行」を探します。
その検索方法が以下です。
パターン1 検索したい文字の位置を基準に考える。
「”-“」が発生する箇所をまず考えます。
すると、このようになります。
これは肯定先読みというもので、「パターンに合致しているものの先頭の位置にマッチするよ」という意味を持ちます。
サクラエディタで実施するとこんな感じです。
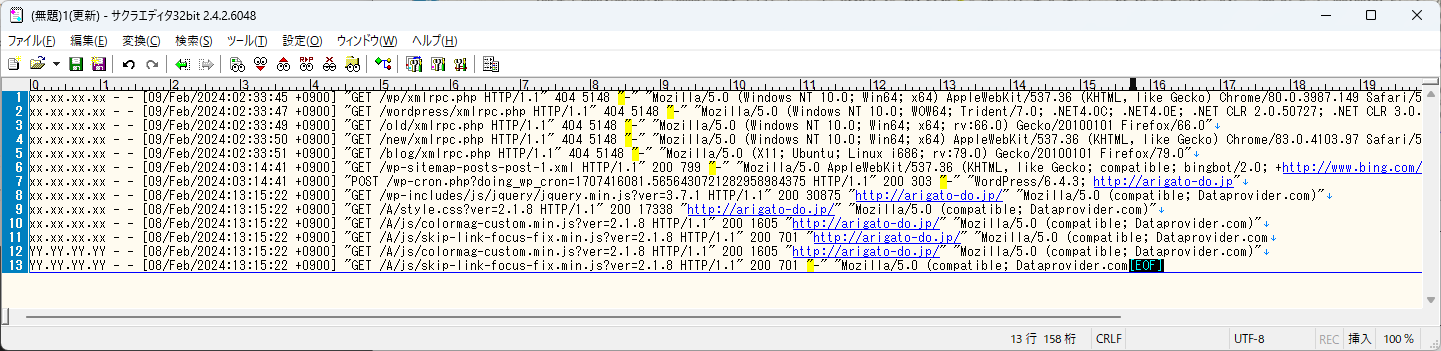
サクラエディタの表示の仕方が分かりづらいですが、これは「”」にマッチしているわけではありません。
「”」の直前の位置にマッチしています。
「文字」ではなく「位置」にマッチしています。
そのため、「(?=”-“)」を対象として空白で置換しても

「”」を後ろにつけた「(?=”-“)”」で検索しても
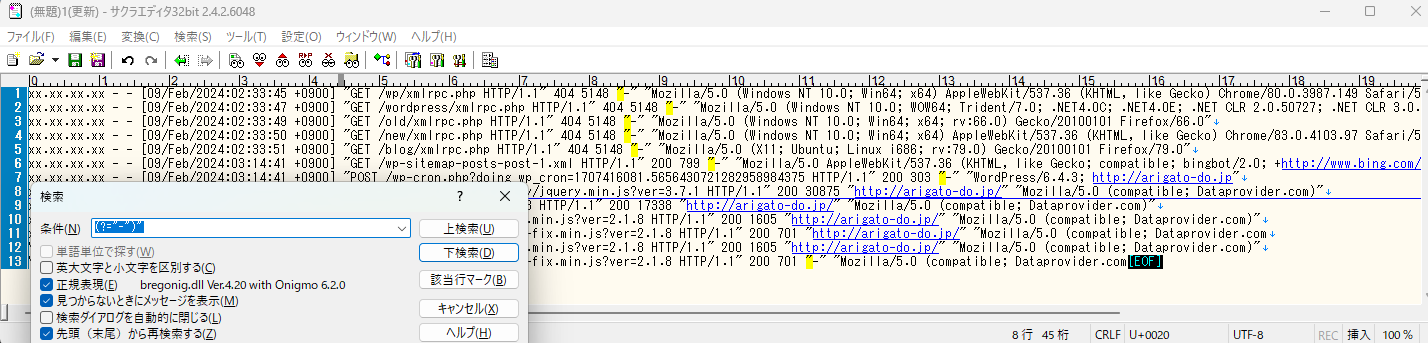
何も変わらないですね。
「(?=)」は文字ではなく位置にマッチすると覚えましょう。
さて、(?=”-“)で「”-“」の位置が分かったので、あとは簡単です。
「”-“」の前後をすべてマッチするように、「任意の文字が0文字以上」を意味する「.*」を使って
とすると1行選択できます。こんな感じです。
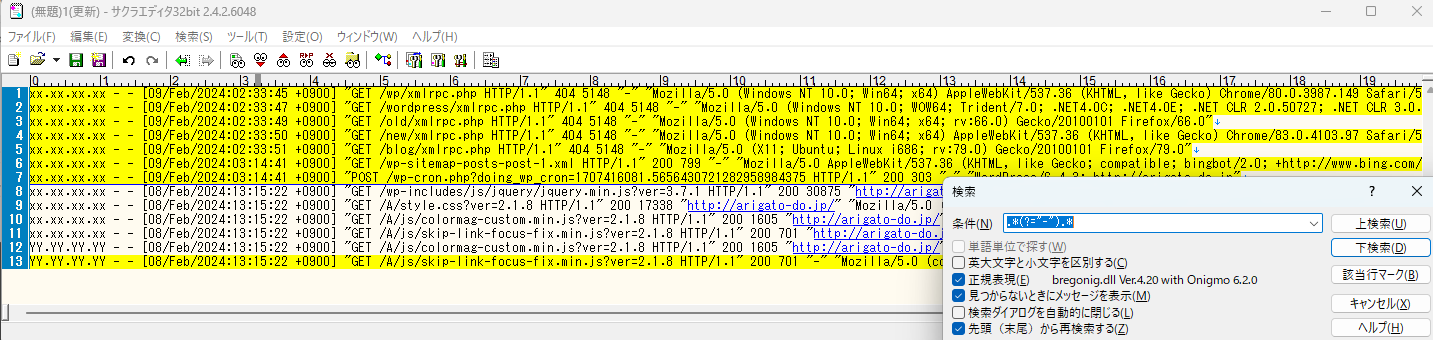
xx.xx.xx.xxで始まる1行を見つけたいので、「先頭xx.xx.xx.xxで始まる」という意味で
「^xx\.xx\.xx\.xx」を追加してあげましょう。
\を付けることで、正規表現で意味を持ってしまう「.」を、文字としての「.」としてくれます。

抽出できましたね!!
これで不正アクセスしている人への対策ができそうです。
他のパターンでの抽出も試してみましょう。
パターン2 検索したくない行を省いた後、抽出する
「「http://arigato-do.jp/」が存在している箇所は不正アクセスではない」という考えで、まずは「http://arigato-do.jp/」が含まれる行を検索してみましょう。
特に特別な表現は無い(.は\でエスケープします)ため、前後に「.*」を付けて行抽出してみます。
「http://arigato-do.jp/」が存在している行が抽出されましたね。
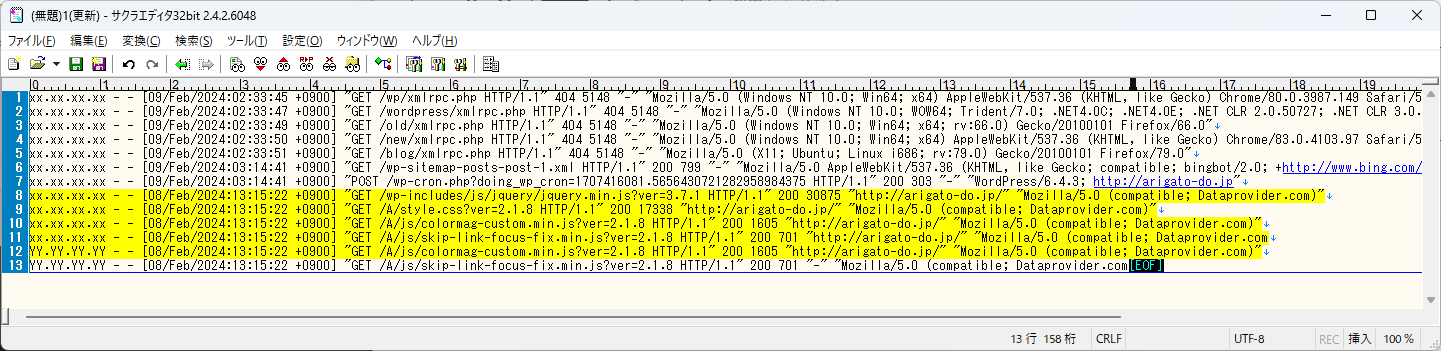
正直いうと、こんな感じでこのまま空白で置換してしまえば必要なログだけが残るので、抽出したと言えなくもないです。

ただそれだと面白くないので、位置にマッチする正規表現を使って、対象外の文字も残しつつ、対象の行を抽出します!
ずばり「(?!)」を使いましょう!これは否定先読みと呼ばれるもので、「対象文字の先頭位置に一致しない、全ての位置」にマッチします。
検索すると以下のようになります。

対象文字「http://arigato-do.jp/」の「先頭の位置以外」がすべてマッチしている状態です。
つまり、対象外としたい「http://arigato-do.jp/」が含まれる行の中に、マッチしない箇所を一つ作ることができることになります。
となると、「「http://arigato-do.jp/」が含まれる行の先頭をマッチしないようにする」ことと、「先頭から末尾までをマッチする」を合わせれば、目的が達成できそうです。
以下のように検索してみましょう。
これは、「先頭(^)から末尾($)まで」を表す「^.*」の間に「対象外の文字が入っている行の先頭を非マッチ((?!.*http://arigato-do.jp/))」を挟むことで、「対象外の文字を含む行の先頭を「^」でマッチできないようにしています。
その結果、対象外の文字を含む行が抽出対象から外れるのです。
あとは以下のようにすれば、悪い奴の動きを終えるわけです。

今回は以下の方法でログを抽出しました。
^xx\.xx\.xx\.xx(?!.*http://arigato-do\.jp/).*$
他にも抽出の仕方があると思うので、いろいろ試してみると面白いかと思います。
正規表現の勉強は、この本を参考にすればいいかなと思います。